
My attempt at solving the “Einstein Puzzle”, seen recently on Reddit’s /r/math.
The puzzle is described in this image (with accompanying discussion on Reddit) It’s possible the connection with Einstein is merely apocryphal — but that’s probably a good thing, because combinatorics is relatively easy compared to general relativity.
Because of its discreteness and rule-based description, it leaps out as a problem possibly suited to a solution in Prolog. Applying a rule may result in later contradictions, so backtracking is an element of the problem. Backtracking can be implemented in any language (see my earlier AI player), but Prolog has it built in. And so, since I was in need of refreshing my skills, I started work on that, even before I made any serious attempt at solving it mentally.
There are k = 6 fields, each of which has n = 5 distinct values. The fields are: house number, nationality, house colour, favourite drink, pet, brand of cigarette. (Perhaps to update the problem for modern sensibilities I should have substituted “favourite model of smart phone” as the last field…)
Without loss of generality (hah! I’ve always wanted to say that), we can assume the house numbers are in fixed order 1,2,3,4,5. That leaves k-1 = 5 independent permutations on the remaining fields. Ignoring the constraints, there are 
Attempt 1. Generate-and-test
This is the brute-force approach. We define a predicate valid(Sol) that unifies Sol with any valid solution. In this program, a valid solution is one in which all houses, people, drinks etc. appear, and are unique in each field. (So a solution where both the German and the Swede like dogs is not valid.)
But first we need to come up with a representation. A solution is the set of permutations of each of those fields. Alternatively, it is a record of who lives in each house, what colour it is, and what they drink, smoke, and keep as pets. It’s essentially a matrix, with one row per house and one column per field. For instance:
| House number | Nationality | House colour | Drink | Pets | Cigarettes |
|---|---|---|---|---|---|
| 1 | english | red | tea | cats | blend |
| 2 | german | green | coffee | dogs | dunhill |
| 3 | norwegian | blue | milk | horses | pallmall |
| 4 | swedish | yellow | water | fish | bluemasters |
| 5 | danish | white | bier | birds | prince |
We earlier translated the problem from one of finding a set of 6-tuples — whose first elements were the unique values 1-5 — into one of finding an ordered list of 5-tuples. This translation not only cuts down the problem space by removing one of the permutations; it makes for easier representation and processing in Prolog. Lists are natural in Prolog, but sets are less so (and are typically implemented as lists in which we must ignore order, and must enforce distinctness).
The representation is a list of lists: each cell is a member of one of the five fields. Checking the validity is done by providing a supply of field values and processing each row recursively. Every cell in the row must appear in the corresponding list in the supply; it then exhausts that item and the remaining supply is used to check the validity of the tail of the solution.
valid(Sol) :-
Supply = [[english, german, norwegian, swedish, danish], [red, green, blue, yellow, white], [tea, coffee, milk, water, bier], [cats, dogs, horses, fish, birds], [blend, dunhill, pallmall, bluemasters, prince]],
valid(Sol, Supply).
valid([], [[]|_]).
valid([House|Rest], Supply) :-
valid_house(House, Supply, Remaining),
valid(Rest, Remaining).
Checking a row’s validity is also recursive over the cells, and the corresponding lists in the supply. Prolog’s select predicate helps here: it ensures that an item is present in a list, and removes it, returning the remaining items. Or, in a more logic-programming parlance, it unifies with an item, with a list including that item, and with that list with the item removed. We use it to generate the remaining supply which is “returned to” (or, unified with a variable in) the calling predicate.
valid_house([], [], []).
valid_house([F|OtherF], [S|OtherS], [R|OtherR]) :-
select(F, S, R),
valid_house(OtherF, OtherS, OtherR).
valid(Sol) is successful if the validity check reaches the base case where an empty table is valid when the supply is also empty. (I have cheated in the rule valid([], [[]|_]). above; the program only checks that the first supply list is empty. This should be adequate since all supply lists are initially the same length, and items are removed from them in unison.)
Let’s test valid(Sol), starting with a smaller problem of two houses and two non-house fields. First, check that it generates all the valid results:
?- valid(S, [[english, american], [tea, coffee]]). S = [[english, tea], [american, coffee]] ; S = [[english, coffee], [american, tea]] ; S = [[american, tea], [english, coffee]] ; S = [[american, coffee], [english, tea]] ; false.
Then try with an additional rule (“The Englishman drinks tea.”) to test each one before accepting it:
?- valid(S, [[english, american], [tea, coffee]]), member([english, tea], S). S = [[english, tea], [american, coffee]] ; S = [[american, coffee], [english, tea]] ; false.
Seems to work, and near-instantaneously too. Let’s also check that it generates the number of solutions we expect for a slightly larger problem:
get_time(T1), findall(S, valid(S, [[english, danish, norwegian, swedish, german], [tea, coffee, milk, water, bier]]), R), length(R, X), get_time(T2), TD is T2-T1. T1 = 1.3159e+09, R = [[[english, tea], [danish, coffee], [norwegian, milk], [swedish, water], [german, bier]], [[english, tea], [danish, coffee], [norwegian, milk], [swedish, bier], [german, water]], [[english, tea], [danish, coffee], [norwegian, milk], [german, water], [swedish|...]], [[english, tea], [danish, coffee], [norwegian, milk], [german|...], [...|...]], [[english, tea], [danish, coffee], [norwegian|...], [...|...]|...], [[english, tea], [danish|...], [...|...]|...], [[english|...], [...|...]|...], [[...|...]|...], [...|...]|...], X = 14400, T2 = 1.3159e+09, TD = 0.254081.
That problem, with people and their drinks in five houses had 


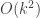
We could implement the remaining rules. But this method requires generating all valid solutions first; additional rules are not going to cut down the amount of work.
Attempt 2. Fill in a template
What if, instead of generating complete solutions and discarding most of them, we start with a completely empty solution and progressively fill it in?
Let’s make a predicate that creates the initial empty solution.
template([R1, R2, R3, R4, R5]) :-
template_row(R1),
template_row(R2),
template_row(R3),
template_row(R4),
template_row(R5).
template_row([_, _, _, _, _]).
We need to use distinct variables for each row — otherwise, if the same variable is used, the program will try to find solutions that bind the same value to each of those variable occurrences. The same applies at the the cell level, but as we do not need to ensure any particular structure for a cell, we can use Prolog’s shorthand _ variable, which is a new, unique variable in each place it occurs in a rule.
?- template(Sol). Sol = [[_G324, _G327, _G330, _G333, _G336], [_G339, _G342, _G345, _G348, _G351], [_G354, _G357, _G360, _G363, _G366], [_G369, _G372, _G375, _G378, _G381], [_G384, _G387, _G390, _G393|...]].
It’s a bit hard to read the solution, so we can create a predicate that prints it more prettily:
print_template([]) :- nl.
print_template([H|T]) :-
print_template_line(H),
print_template(T).
print_template_line([]) :- nl.
print_template_line([X]) :- print_template_cell(H), nl.
print_template_line([H,H2|T]) :-
print_template_cell(H),
write(','),
print_template_line([H2|T]).
print_template_cell(X) :- var(X), write('_').
print_template_cell(X) :- \+var(X), write(X).
Let’s implement the first rule (“The Englishman lives in the red house.”) and see how it goes:
action1(T) :-
member([english, red, _, _, _], T).
All this predicate does is check that the given tuple occurs in the solution matrix. Note that it does not check that it only occurs once! But let’s test it:
?- template(Sol), action1(Sol), print_template(Sol), fail. english,red,_,_,_ _,_,_,_,_ _,_,_,_,_ _,_,_,_,_ _,_,_,_,_ _,_,_,_,_ english,red,_,_,_ _,_,_,_,_ _,_,_,_,_ _,_,_,_,_ _,_,_,_,_ _,_,_,_,_ english,red,_,_,_ _,_,_,_,_ _,_,_,_,_ _,_,_,_,_ _,_,_,_,_ _,_,_,_,_ english,red,_,_,_ _,_,_,_,_ _,_,_,_,_ _,_,_,_,_ _,_,_,_,_ _,_,_,_,_ english,red,_,_,_ false.
It has printed five solutions, each one locating the Englishman and his red house in a different position in the street. Implementing the second rule (“The Swede keeps dogs.”) and applying both rules yields 20 solutions: 5 places the Englishman can go, and for each, 4 remaining for the Swede.
Not all rules are equal. The number of ways of appling a rule to a template can depend on the rule and the state of the template. The ninth rule (“The Norwegian lives in the first house.”) can be applied in exactly one place. So there is some justification in applying it immediately. But this is just an optimisation; if Prolog finds it cannot apply it because previous rules have erroneously occupied its place, it will backtrack until it can.
action9(T) :-
T = [[norwegian, _, _, _, _], _, _, _, _].
Let’s return to the question of rules not checking for uniqueness. We’ll try applying rule 14 (“The Norwegian lives next to the blue house.”) after rule 9.
action14(T) :-
nth1(N, T, [norwegian, _, _, _, _]),
nth1(N2, T, [_,blue, _, _, _]),
D is N2-N,
member(D, [-1,1]).
From a common sense point of view, there’s only one valid application, since the blue house must go next to the Norwegian, and he’s already in the first house: the blue house must therefore be house #2. But the first two solutions with our simple rules are:
?- template(Sol), action9(Sol), action14(Sol), print_template(Sol), fail. norwegian,_,_,_,_ _,blue,_,_,_ _,_,_,_,_ _,_,_,_,_ _,_,_,_,_ norwegian,blue,_,_,_ norwegian,_,_,_,_ _,_,_,_,_ _,_,_,_,_ _,_,_,_,_ ...
The rule has invented a solution in which a Norwegian lives in house #2, and house #1 (already occupied by the first Norwegian) is blue! Since the additional specifications on the first did not conflict with the current bound values, they were accepted.
These rules do not check for validity. As it happens, this does not matter in the long run, because the full set of fifteen rules is sufficient to guarantee unique appearances of all values. By the time the solution is complete, all invalid partial solutions will have been backtracked out of existence. In this instance, the rules specifying the existence of an Englishman, German, Swede and Dane would have eventually caused that strange application to be reversed.
But if we are interested in possible solutions when the problem is not yet completely solved, or if our required uniqueness but the rules alone were not enough to ensure it, we can simply reuse the valid predicate from the first attempt. Validity checking this way will do two things:
- It will filter out invalid solutions, such as second one from above.
- It will generate all possible complete solutions derived from the provided template. This may or may not be desirable. A validity check that does not bind previously unbound cells is left as an exercise.
;-)
All the rules are implemented in the source file einstein.prolog, and are encapsulated in a helper predicate solve(Sol). Running the second attempt on the full problem:
?- template(Sol), solve(Sol), print_template(Sol). norwegian,yellow,water,cats,dunhill danish,blue,tea,horses,blend english,red,milk,birds,pallmall german,green,coffee,_,prince swedish,white,bier,dogs,bluemasters Sol = [[norwegian, yellow, water, cats, dunhill], [danish, blue, tea, horses, blend], [english, red, milk, birds, pallmall], [german, green, coffee, _G468, prince], [swedish, white, bier, dogs|...]] ; false.
Solving this goal is near-instantaneous, because the majority of possible solutions are discarded before they are ever generated. There may be five ways of positioning the Englishman and his red house in rule one; but each constraints the possible applications of future rules, and prunes the solution tree.
Afterword
A final note on what Prolog is doing operationally. In the first attempt, the valid predicate would construct new solutions row by row, and successively bind them to its Sol variable. When a solution was rejected, the predicate would backtrack to its most recent construction decision and rebuild part of it differently.
In the second attempt, there is a single solution, the template, created by template. When rules are applied to it, new templates are not created. Instead, Prolog records bindings for the variables within it. Backtracking does not undo any construction, it just undoes the bindings.
There is not a strong distinction between these two operations, since ultimately all work is done by unification (of bound or unbound terms). And I should not suggest that undoing bindings is necessarily cheaper than undoing constructions. But I feel there is a conceptual difference between taking an incomplete solution and progressively making it more specific, versus taking a complete solution and rebuilding parts of it.
The second attempt described in this post was more efficient. But I think it is also more idiomatic Prolog. It uses unbound variables not just as transient things that should be bound at the earliest opportunity, but as part of the representation of the problem and solution.

{kind=link}
Pingback: Syntax highlighting Prolog | EJRH
Pingback: Pets prolog | Keglerscorner